

「robots.txt」というファイルを作成していますか?
この“robots.txt”とは、クローラーに対してサイト内ページの巡回をブロックするのか、または許可するかどうかを記述して知らせるものです。
そもそもクローラーは、被リンクや内部リンクを辿ってサイト内のページを巡回して更新したデータや新しいページをインデックス・上書きしていくわけですが、このクローリングの数は無限というわけではないため、重要なページを優先してクロールするべきであって、クロールの必要のないページは“robots.txt”によって制御しておくことが重要となるわけです。
そのため、この“robots.txt”をサーバーにアップすることでSEOや検索順位に直接期待できるものではありませんが、正しい評価を受けるためにクローラーの最適化を行うもので、強い強制力はありません。
そのため、重複の改善や“noindex”の代わりに利用するものではないという点が注意点として挙げられ、この辺りの区別をしっかりと理解して“robots.txt”を設置することが大切です。
では、今回は「robots.txt」の記述方法や意味について詳しくご説明していきたいと思います。

目次
robots.txtとは

この“robots.txt”とは、基本的にクロールを行うGoogle検索エンジンなどをはじめとするエージェントを指定し、各ファイルへのブロック・許可の指定を組み合わせてクロールの最適化を行うためのファイルです。
また、下記ヘルプにあるように、クロールの必要のないファイル形式(画像・動画ファイルなど)を指定してブロックすることも可能です。
robots.txt は主に、クローラのサイトへのトラフィックを管理するために使用されます。場合によっては、ファイル形式に応じて Google でページを非表示にするためにも使用されます。
使い方としては、内容を記述してサーバーのトップディレクトリにアップしておくだけで、クローラーがそれをヒントとして読み取り、クロールを制御して巡回していきます。
後ほど詳しくご説明しますが、クローラーは基本内部リンクなどを辿ってページを巡回していくため、デフォルトでは許可の状態です。
そして、特定のディレクトリの中でひとつのページだけ許可したいという場合は、一旦そのディレクトリをブロックし、その中の許可したいページだけを許可と指定するわけです。
そのため、ブロック・許可をうまく組み合わせる必要があるということです。
SEO効果について
次に、この“robots.txt”によるSEO効果についてです。
これは先ほどもご説明した通り、そもそもがクローラーの巡回を制御・指示するヒントとなるようなファイルなので、順位改善に期待できるものではありません。
また、クローラーに巡回するページのブロック・拒否を伝えるためのものなので、一緒にsitemap.xmlへのパスも記述しておきます。
あくまでサイト内を巡回するクロールを最適化して、更新したページや新しいページなど重要度・優先度を考慮してクローラーに早く見つけてもらうためのものです。
※場合によっては旧サーチコンソールの“Fetch as Google”や、新しいサーチコンソールの“URL検査”を利用しましょう。
つまり、クロールの最適化によって順位が改善するわけではなく、クロールを重要なページへ優先的に巡回してもらった結果、検索エンジンに最短で正しく評価されることに期待でき、間接的とは言ってもコンテンツの質が伴わなければ上位表示は期待できません。
参考:Google のクローラ(ユーザー エージェント) – Search Console ヘルプ
キーワード選定におすすめのキーワードツールをご紹介しています。

なぜクロールを最適化するのか?
次に、この“robots.txt”によってなぜクロールを最適化するのか?というと、先ほどもご説明した通り優先させたいページへクロールしてもらうためであって、検索順位を付ける必要のないページ(その他異なるファイル形式)をボットの種類を意味するエージェントとともに指定して、無駄なクロールを除外するためです。
そのため、先ほどもご説明した通りクロールの最適化が必要なければ、そもそもrobots.txtの設置そのものが必要なく、その場合は別途“sitemap.xml”をクローラーのために用意して、サーチコンソール上から送信しておくだけで良いでしょう。
どちらにしてもページ数が多いサイトの場合、こういったクローラビリティに考慮したサイト管理が後々重要となってくるので、コンテンツをどんどん増やしていく予定のサイトは早めに設置しておくとクロールも無駄なく巡回することが可能となります。
robots.txtの書き方

では、具体的な“robots.txt”の記述方法についてご説明していきます。
基本的に“robots.txt”には、ボットの種類を意味するエージェントの指定、そしてページへのクロールのブロック・許可、そしてサイトマップへのパスを下記のように記述してサーバーへアップロードしておきます。
User-agent:* Disallow: Sitemap:https://sample.com/sitemap.xml
そして、全てのページにクロールが必要な場合(クロールをブロックする必要がない場合)には、このrobots.txtの設置は必要ありません。
あくまでクロールの最適化が目的なわけで、検索結果に表示する必要のないページは“noindex”を付与し、なおかつrobots.txtにクロールのブロックを指定しておくことで、重要なページを優先的にクロールしてもらうことを促すということを理解しておきましょう。

User-agent
ではまず1行目に記述する“User-agent”についてです。
この“User-agent”とは、クロールを行うボットの種類を意味し、検索エンジンであるGoogleだけでも“Googlebot”をはじめ画像用、アドセンス用など様々なクローラーが存在します。
参考:Google のクローラ(ユーザー エージェント) – Search Console ヘルプ
そして、他にも様々なクローラーが存在し、中でも過去のサイトを随時クロールしている“インターネットアーカイブ(ia_archiver)”にキャッシュを残したくない場合にも、このエージェントの指定が必要となり、複数指定する場合は改行して追加していきます。
また、全てのクローラーを一括で指定する際は、「*(アスタリスク)」を記述しておきます。これによって全てのクローラーへの指示となります。(例外もあり)
Disallow・Allow
次に、“Disallow(クロールの拒否)”と“Allow(クロールの許可)”を組み合わせてクロールの必要がないページを指定していきます。
というのも、基本的にクローラーは被リンクや内部リンクを辿ってページをクロールしていくため、robots.txtを設置していない状態でもサイトを巡回していきます。
そのため、このrobots.txtではクロールの拒否だけを指定することになります。
しかし記事数も多く、階層の深いディレクトリのたったひとつの記事だけを許可したい場合、それ以外を全て“Disallow”指定しなければいけないことになり、こういった場合にはまずディレクトリへのクロールを一括で拒否しておいて、次にその中のひとつの記事を“Allow”指定するといった記述によって簡潔にクローラーへの指示をまとめることができるというわけです。
こちらも複数あれば改行して記述しておきましょう。
記述する際の注意点について

次に“robots.txt”を記述する際の注意点についてご説明します。
基本的に“robots.txt”はクロールの補助的な役割を果たすため、強い強制力を持ちません。そのため、本当にクロールされたくないものや、そもそもインデックスの必要がないページに対する最適な方法というわけではないことを理解しておくことが大切です。
また、先ほどご説明したエージェントの指定、クロールのブロック・許可の指定をひとかたまりとして考えて、下記のようにエージェントごとのクロールを指定することが可能です。
参考:robots.txt ファイルを作成する – Search Console ヘルプ
User-agent:Googlebot-Image Disallow:/img/ User-agent:* Disallow:/contact/ Sitemap:https://sample.com/sitemap.xml

アップロード場所
上記のように記述した後、robots.txtファイルをサーバーの階層ではなくトップディレクトリにアップロードしておきます。
そして注意点として、“robots.txt”は置き場所・ファイル名も決められているのため、設置してあれば誰でも確認することができるということにもなり、特に重要なページをアップしていて、クロール拒否するために“robots.txt”にそのディレクトリやページを記述していた場合、重要とされるページが特定されてしまいます。
その際、クローラーだけでなくユーザーに対しても閲覧制限を行うために“noindex”の記述はもちろん、場合によってはベーシック認証を設定しておきましょう。
重複コンテンツの対策に利用しない
次に、サイト内に記事数が増えてくると重複したコンテンツが混在する場合もあるかと思いますが、こういった場合に“robots.txt”を使用するというのも間違った使用方法となります。
robots.txtにてクロールを制限したとしてもインデックスしないというわけではないため、確実に検索結果から除外した場合は“noindex”を使用しましょう。
あくまで重複コンテンツはリライトや記事同士の統合、または削除によって対応することが大切です。
キーワード選定に悩んでいませんか?
動作確認を行う

上記のようにrobots.txtを記述し、アップロードした後は念のため動作確認しておきましょう。
これは、サーチコンソールで簡単に行うことができますが、新しいサーチコンソールにはまだ実装されていないようで、旧サーチコンソール上から行います。
robots.txtテスター
この“robots.txt”の動作確認を行うには、サーチコンソールの“クロール”>“robots.txt テスター”へ進みます。(旧サーチコンソール)
こちらには、アップロードしたsitemap.txtの情報が表示されているかと思います。
そして、ここではその内容を書き換えることができ、エージェント・ディレクトリやページを指定して、正しく動作しているかどうかチェックすることができます。
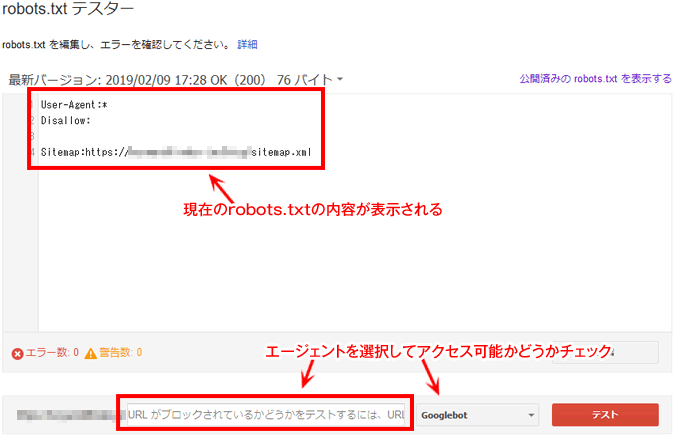
また、ここでテストした内容をダウンロードすることもできます。(この画面上ではアップロード・更新などはできません。)
フォーム右下に表示されている“送信”というボタンをクリックすると以下3種類の項目がポップアップで表示されるので、チェック後の内容をダウンロードしたい場合は“ダウンロード”ボタンをクリックします。
- 更新されたコードをダウンロード
- アップロードされたバージョンを確認
- Google に更新をリクエスト
他にも現状の“robots.txt”を確認したい場合は“アップロードされたバージョンを確認”をクリック、改めてサーバーにアップした後は“送信”をクリックして更新されたことを伝えます。
その場合は、一旦作成した“robots.txt”をダウンロードして、サーバーにアップし、さらにサーチコンソール上から“送信”を行います。
まとめ
今回は、サイトのクロールを最適化するための「robots.txt」の書き方や意味についてご説明しました。
この“robots.txt”は直接的に検索順位を上げるためのものではありませんが、検索エンジンがランキングするためのインデックスを行うクローラーの最適化といった意味で、サイトによっては非常に重要な要素ともなり得るクローラビリティに関するファイルです。
ユーザーにとってはもちろん、クローラーに対しても巡回しやすいサイト作りを心がけましょう。






